
An estimated 3.1 billion people currently have access to the Internet. That’s nearly 50% of the planet’s population. And of those 3.1 billion, approximately 44.3% shop online. Using simple math, that means there are around 1.37 billion looking to buy goods online.
With so many potential customers to be found online, you likely already have a website or are looking to put one together. But do you know how exactly how the web works? Having a deeper understanding of the Internet can play a crucial role in successfully running a commercial website. Here’s a quick rundown to get you started.
1. Requests and Responses
The majority of web interactions can be broken up into two categories – requests and responses. Requests are what your browser/app/API sends to the server, requesting data, and the response is, well, the response.
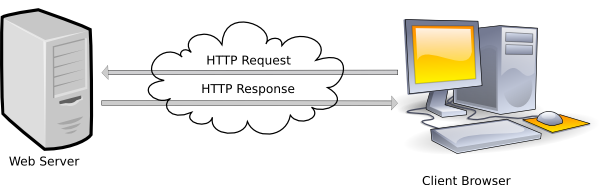
When your browser loads a page, it makes multiple HTTP (HyperText Transfer Protocol) requests – one for each file loaded on that page. Each individual image, javascript file and css file gets an individual HTTP request.
After the client sends these requests, the server will receive them, process them and return a response. These responses tell the browser the result of the request via a 3 digit code. A list of all HTTP status codes can be found here, but the most common ones you’ll see are:
- 200 – OK – The request was successful, and the file was returned as a result. This is the standard response to a request.
- 301 – Permanent Redirect – Used for redirecting the client to another file. Useful especially when launching a new site to take old urls and redirect them to new pages. A 301 redirect will change the url to the new page url if used in an .htaccess capacity.
- 302 – Temporary Redirect – Used for redirecting the client to another file while preserving url structure.
- 304 – Not Modified – Used to determine if a resource has been cached or not. If your web server is set up properly, use of 304s can reduce page load times drastically by not pulling new data each time.
- 403 – Forbidden – If a resource is behind some form of authentication, that authentication must be present in the request for the file to be accessed. This is useful when dealing with a user management system, allowing certain accounts to request files and disallowing others.
- 404 – Not Found – Oops! A 404 error is the most common error on the internet. It happens when a request tries to access a resource that doesn’t exist, whether that’s through a misspelled URL, or through a missing file.
- 500 – Internal Server Error – A 500 error happens when there’s a problem with an action the server tried to perform. Typically, it’s seen when you have an error in code written in a server side language, such as PHP.
2. URL Structure
A URL is comprised of several parts. Take the following URL for example:
http://video.google.com:80/video.php?play=yes#action
URL structure can be a little overwhelming to someone who doesn’t work with the web every day, so I’m going to do what I can to make it more relatable.
- The first part of this URL, the http://, is known as the protocol. Common ones on the web are http:// and https://, with the s indicating a secure http request. This can also be file:// or ftp:// or many other protocols. If you think of a house, this would be the equivalent of how you get to that house. Do you drive there? Walk? Take a bus? All of those methods end up at the same place, but by different means.
- The next part is the video.google.com. This is known as the host, or hostname, and is comprised of a subdomain, video, a domain, google and a TLD, or Top Level Domain, .com. Going along with our house analogy, this would be the street address for the house.
- :80 is a port. 80 is the default port for web servers, and as such, is typically not found in the URL structure. However, a server can be displaying content on multiple ports, such as 8000, or 8080 etc. SSL requests are typically served over port 443. A port would be instructions on which door to use to get into the house. The majority of people coming in are going to come in through the front door.
- /video.php?play=yes#action is the request URI. Request URIs are like instructions for what you want the server to do. In this scenario, we’re asking the server for the file video.php with the parameter of play set to yes, and the anchor action. The request URI in house terms, would be the directions you give someone inside the house to get to a specific room. Essentially, it’s the same as “Go down the hall, up the stairs and it’s the first door on your right.”
- /video.php is the file path. This typically refers to the location of the file on the server. Think of this as the specific room you’re looking for in the house, such as a living room, or a bedroom.
- ?play=yes is a parameter. URLs can have lots parameters. Parameters start with a question mark (?) and are separated with an ampersand (&). Parameters are specialized instructions for that specific page, such as an account ID, or the page number you’re on in a large list of records. Parameters work similarly to if you were asked to perform a task within a room, such as making a salad while in the kitchen, or changing the channel on the TV in the living room. It doesn’t describe where the action takes place – just the nature of the action itself.
- #action is a named anchor. Anchors can be used in navigation to go to a specific part of a page. They typically refer to an internal section of the document. This would be similar to if you were directed to the living room, and then specifically told to focus on the couch.
3. How It All Comes Together
That was a lot of information. Understandably, it might be a little much to take in all at once, though hopefully that sheds a little light into the basic building blocks of every day web usage. But how does that apply to your website and your business? Let’s walk through what happens when someone visits your site, running it through the different building blocks.
First, a user tells their browser that they would like to access your site. This either comes in the form of them typing your URL directly into their browser bar, or clicking on a link to your site from any number of sources – ads, referral pages, Facebook, etc.
The browser then sends out a request to the Internet, asking for the filename specified in the URL, located at that particular domain. The server that the URL refers to will then respond with one of the response codes listed above. For the sake of demonstration, we’ll say that the server responded with a 200 request, which means that the file was found, and the request was successful. The server responds with the file requested, giving the browser lines of code to display as a website. This code is usually returned as HTML. The browser goes line by line through the HTML, following the code’s instruction to display the site.
As the browser works through that page, it loads external Javascript, CSS and image files. Whenever the browser comes across any of these files, it stops processing any more HTML code and sends the server a request for the file. The more files you have to request, the slower the page loads.
Load time is crucial. According to KISSMetrics, 40% of users abandon a page after 3 seconds of loading — which is why understanding how the web works can impact your business. Not only does that affect those users, but those users are 44% likely to tell their friends about their poor experience, leading to even more users that you’re missing out on. As the web grows, successful sites are those that are performant.



